Open MPI是MPI的一种开源、成熟的实现方式,它在开发初期整合了了田纳西大学的FT-MPI、Lose Alamos国家实验室的LA-MPI、印第安纳大学的LAM/MPI与斯图加特大学的PACX-MPI[34]四个项目技术与资源,由上述四个机构组成最初的开发团队,旨在使用来自各个项目的最佳思路和技术。
Open MPI的设计以MPI组件架构(MPI Component Architecture, MCA)为中心,具有较好的扩展性,实现集合通信功能的框架也位于MCA架构中。
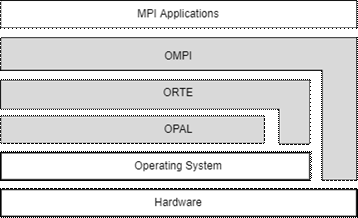
Open MPI实现架构
Open MPI的设计以MPI组件架构(MPI Component Architecture, MCA)为中心,由MCA、Component frameworks、Modules三个主要功能模块组成,其中Modules是自包含的软件单元,实现了定义好的接口,可以在运行时与其他模块组合,为其他层提供基础服务;Component frameworks负责实现Open MPI每一项具体任务相应的功能,管理与协调Modules;MCA作为主干管理并为其他层提供服务,例如从更高抽象层次接受运行时参数,并通过组件框架将其传递给各个独立的模块。
Open MPI基于组件的实现方式使其具有较强的可扩展性,经过诞生至今近二十年的发展,在开发团队以及第三方开发人员的不断努力下Open MPI已经拥有十分丰富的功能。4.1版本的Open MPI在代码结构上仍由OPAL、ORTE、OMPI三个抽象层组成,其总体的抽象架构视图如图所示,三个抽象层在调用时遵循上下层关系,即每一层内的组件只能调用同一层或更低层次的框架提供的功能。三个抽象层各自的功能以及一些常用框架的介绍如下。
OPAL(Open, Portable Access Layer) 是Open MPI抽象的最底层,它的抽象集中于一个个独立的过程而非并行作业,主要提供了一些工具程序和胶水代码,如通用链表、字符串操作、调试控件和其他普通但必要的功能。OPAL还提供了一些在不同操作系统内核中都能够运行的功能,如发现IP接口、共享内存通信、高精度计时器等,使Open MPI具有良好的可移植性。OPAL层常用的框架有点到点字节传输层btl,负责使用不同的网络协议将数据由发送方传输给接收方;memcpy框架用于支持内存拷贝;timer框架用于提供高精度的计时器。
ORTE(Open MPI Run-Time Environment) 负责支持不同的后端运行时系统。要实现MPI不仅必须提供所需的消息传递API,还必须提供一个附带的运行时系统来启动、监视和终止并行作业,这正是ORTE层的功能。Open MPI的并行作业由一个或多个进程组成,这些进程可能跨越多个操作系统实例,并被绑定为一个内聚的单元。在小规模或没有分布式计算支持的环境中ORTE仅使用rsh或ssh启动并行作业中的单个进程,而在具有调度程序和资源管理器的高级环境中ORTE可以通过它们提供的API启动与管理作业进程,目前ORTE层支持的环境包括PBS Pro和Torque、LSF、SLURM、Oracle Grid Engine以及Cray XE, XC, XK等。
OMPI(Open MPI)是最高抽象层,也是唯一向应用程序公开的层,MPI的API以及MPI标准定义的消息传递语义均是在这一层实现。在OMPI层中实现的框架有集合通信框架coll,其中实现了MPI定义的集合通信操作的接口以及各种集合通信算法,本文的研究也将主要实现于coll框架中;MPI点对点通信管理层框架pml,在MPI层和所有可用的btl模块之间提供消息分片、调度和重组服务;归约操作框架op,用于MPI 内部约简操作的后端函数(如MPI_SUM)。
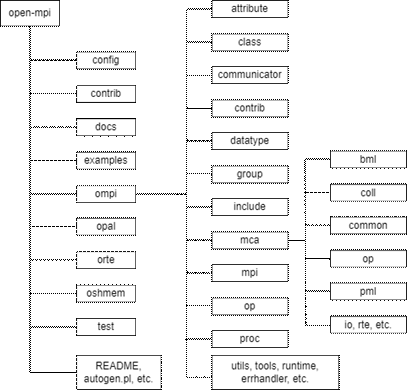
Open MPI源程序结构
开发新的MCA组件需要在Open MPI源码上进行改动,以4.1版本Open MPI为例,如图所示,三个抽象层分别对应./opal、./orte、./ompi三个目录,MCA架构下的框架(framework)位于三个目录下的./mca中。
ompi/mca目录下的子目录是用于实现OMPI层功能的框架(framework),如上一节中举例的coll、pml、op等,它们的目录名与框架名一致,一个框架中一般会有一个或多个实现具体功能的组件(component),一般至少会有一个实现具体功能的base组件。以coll框架为例,coll/coll.h文件中定义了集合通信框架要实现的功能接口,以及框架中通用的数据类型。coll/base目录中的base组件实现了基本的MPI集合通信算法,并能够按照组件优先级为框架选择实际使用的组件。其余的组件如libnbc[37]、tuned[38]等从不同角度优化了集合通信算法,扩展了框架的功能。
在一个现有框架下开发新的组件的过程是相似的,本篇博客后续篇幅介绍在集合通信框架coll下开发组件的步骤。
开发新的集合通信组件
Open MPI开发新组件相关的资料较少,现有只找到了两篇相关的文章:
除此之外仅能参考框架中现有组件实现。由于集合通信算法是MPI相关研究中比较热门的一个方向,coll中目前有许多现成的组件,官方还提供了一个demo组件来说明一个集合通信组件必须的组成部分,因此这里就以demo组件源码为基础按顺序介绍开发步骤。
Automake&Autoconfig
Open MPI的Makefile文件由Automake、Autoconfig、Autogen三个工具进行,开发一个新的组件时至少需要在目录下新建一个Makefile.am文件来配置编译相关信息。
sources指定了组件中需要参与编译的文件列表。component_noinst和component_install设置动态构建与静态构建后对应的库名,自己开发组件时将demo替换为组件名即可。同理mca_coll_demo_la_SOURCES、mca_coll_demo_la_LDFLAGS、mca_coll_demo_la_LIBADD三个参数仍需要改成对应的名字,若有特别的编译选项或着要额外加载库分别在后两个参数中设置即可,一般进行开发时按照这里的默认设置即可。libmca_coll_demo_la_SOURCES和libmca_coll_demo_la_LDFLAGS也是这样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 # ./ompi/mca/coll/demo/Makefile.am # Source files sources = \ coll_demo.h \ coll_demo_allgather.c \ coll_demo_allgatherv.c \ coll_demo_allreduce.c \ coll_demo_alltoall.c \ coll_demo_alltoallv.c \ coll_demo_alltoallw.c \ coll_demo_barrier.c \ coll_demo_bcast.c \ coll_demo_component.c \ coll_demo_gather.c \ coll_demo_gatherv.c \ coll_demo_module.c \ coll_demo_reduce.c \ coll_demo_reduce_scatter.c \ coll_demo_scan.c \ coll_demo_exscan.c \ coll_demo_scatter.c \ coll_demo_scatterv.c # Make the output library in this directory, and name it either # mca_<type>_<name>.la (for DSO builds) or libmca_<type>_<name>.la # (for static builds). if MCA_BUILD_ompi_coll_demo_DSO component_noinst = component_install = mca_coll_demo.la else component_noinst = libmca_coll_demo.la component_install = endif mcacomponentdir = $(ompilibdir) mcacomponent_LTLIBRARIES = $(component_install) mca_coll_demo_la_SOURCES = $(sources) mca_coll_demo_la_LDFLAGS = -module -avoid-version mca_coll_demo_la_LIBADD = $(top_builddir)/ompi/lib@OMPI_LIBMPI_NAME@.la noinst_LTLIBRARIES = $(component_noinst) libmca_coll_demo_la_SOURCES = $(sources) libmca_coll_demo_la_LDFLAGS = -module -avoid-version
这个文件并不必要,应该需要开发的组件需要依赖特定的库时才有用。如CUDA组件中该文件设定当Open MPI配置为支持CUDA时才编译该组件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # ./ompi/mca/coll/cuda/configure.m4 # MCA_coll_cuda_CONFIG([action-if-can-compile], # [action-if-cant-compile]) # ------------------------------------------------ AC_DEFUN([MCA_ompi_coll_cuda_CONFIG],[ AC_CONFIG_FILES([ompi/mca/coll/cuda/Makefile]) # make sure that CUDA-aware checks have been done AC_REQUIRE([OPAL_CHECK_CUDA]) # Only build if CUDA support is available AS_IF([test "x$CUDA_SUPPORT" = "x1"], [$1], [$2]) ])dnl
coll_demo.h
每个组件都需要有一个这样命名的头文件,其中定义的内容主要有component结构体、module结构体、引出的函数,其中引出的函数包括有MCA框架内的函数如component的init_query、comm_query,module的enable,还有实现的集合通信函数。
demo组件中没有额外定义component结构体,而是直接使用base组件定义的结构体,如果你组件功能的实现需要在结构体中定义额外的参数则需要重新实现。这里放一个自己在做的集合通信组件的代码作为参考。可以看到在component和module结构体中一个base组件的结构体都是必须的,且需要放在第一个变量的位置。
mca_coll_base_comm_coll_t underlying是一个用来保存现有集合通信函数与实现它的组件的module的一个结构体,算是一个功能性的变量,比如在你组件module进行一些初始化工作时需要进程间集合通信,但此时集合通信函数的实际实现已经由你自己组件来做了,又由于你组件的module还在初始化导致集合通信函数还不能用,这时就只能使用别的组件实现的集合通信函数,集合通信框架下组件的构造方式使这一点能够实现。在Open MPI中,每当一个通信域被初始化时,MCA框架会在目前可用的组件中逐个调用其module的comm_query函数检查其是否可用,可用则进一步用它的函数和组件来设置集合通信api,首先构建的是base组件,它不需要额外的集合通信且在任意通信域都是可用的,这就确保了在构建别的组件前存在可用的集合通信组件与api,在自己的组件构造时如果需要用到集合通信函数,即可先将其存储在underlying中,在需要调用时直接使用。这些基于自己调试程序与阅读源码时的分析,可能详细步骤由错误的地方,但原理上应该是正确的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 #ifndef MCA_COLL_NSA_EXPORT_H #define MCA_COLL_NSA_EXPORT_H #include "ompi_config.h" #include "mpi.h" #include "ompi/mca/mca.h" #include "ompi/mca/coll/coll.h" #include "ompi/communicator/communicator.h" #include "coll_nsa_debug.h" #include "coll_nsa_topo.h" BEGIN_C_DECLS typedef struct mca_coll_nsa_component_t { mca_coll_base_component_2_0_0_t super; int priority; int nsa_output; int nsa_verbose; bool nsa_enable; } mca_coll_nsa_component_t ; OMPI_MODULE_DECLSPEC extern mca_coll_nsa_component_t mca_coll_nsa_component; typedef struct mca_coll_nsa_module_t { mca_coll_base_module_t super; mca_coll_base_comm_coll_t underlying; bool enabled; uint16_t flags; int cw_rank, cw_size; int *rank2row; TOPO_LVL_T topo_lvl; } mca_coll_nsa_module_t ; OBJ_CLASS_DECLARATION(mca_coll_nsa_module_t ); int mca_coll_nsa_init_query (bool enable_progress_threads, bool enable_mpi_threads) ;mca_coll_base_module_t *mca_coll_nsa_comm_query (struct ompi_communicator_t *comm, int *priority) ;int mca_coll_nsa_module_enable (mca_coll_base_module_t *module, struct ompi_communicator_t *comm) ;END_C_DECLS #endif
coll_demo_component.c
首先是组件version的说明性字符串与需要在整个组件中使用的全局变量。若自己定义了新的组件这两个全局变量可以实现在组件的结构体中。
1 2 3 4 5 6 7 8 9 10 11 const char *mca_coll_demo_component_version_string = "OMPI/MPI demo collective MCA component version " OMPI_VERSION; int mca_coll_demo_priority = -1 ;int mca_coll_demo_verbose = 0 ;
其次是局部函数,这里的register是注册MCA参数,注册后可以在mpirun运行程序时通过增加命令行参数-mca <key> <value>来在运行时设置。局部函数还可以根据需要自行定义。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 static int demo_register (void ) ;static int demo_register (void ) { mca_coll_demo_priority = 20 ; (void ) mca_base_component_var_register(&mca_coll_demo_component.collm_version, "priority" , NULL , MCA_BASE_VAR_TYPE_INT, NULL , 0 , 0 , OPAL_INFO_LVL_9, MCA_BASE_VAR_SCOPE_READONLY, &mca_coll_demo_priority); mca_coll_demo_verbose = 0 ; (void ) mca_base_component_var_register(&mca_coll_demo_component.collm_version, "verbose" , NULL , MCA_BASE_VAR_TYPE_INT, NULL , 0 , 0 , OPAL_INFO_LVL_9, MCA_BASE_VAR_SCOPE_READONLY, &mca_coll_demo_verbose); return OMPI_SUCCESS; }
还需要实例化全局唯一一个组件结构体的变量,在需要使用的时候extern来引出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 const mca_coll_base_component_2_0_0_t mca_coll_demo_component = { .collm_version = { MCA_COLL_BASE_VERSION_2_0_0, .mca_component_name = "demo" , MCA_BASE_MAKE_VERSION(component, OMPI_MAJOR_VERSION, OMPI_MINOR_VERSION, OMPI_RELEASE_VERSION), .mca_register_component_params = demo_register, }, .collm_data = { MCA_BASE_METADATA_PARAM_CHECKPOINT }, .collm_init_query = mca_coll_demo_init_query, .collm_comm_query = mca_coll_demo_comm_query, };
该文件最后两个函数与一个宏定义也可以放在coll_demo_module.c中,二者的作用是初始化和释放module中的资源,个人认为放在coll_demo_module.c更合理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 static void mca_coll_demo_module_construct (mca_coll_demo_module_t *module) { memset (&module->underlying, 0 , sizeof (mca_coll_base_comm_coll_t )); } #define RELEASE(module, func) \ do { \ if (NULL != module->underlying.coll_ ## func ## _module) { \ OBJ_RELEASE(module->underlying.coll_ ## func ## _module); \ } \ } while (0) static void mca_coll_demo_module_destruct (mca_coll_demo_module_t *module) { RELEASE(module, allgather); RELEASE(module, allgatherv); RELEASE(module, allreduce); RELEASE(module, alltoall); RELEASE(module, alltoallv); RELEASE(module, alltoallw); RELEASE(module, barrier); RELEASE(module, bcast); RELEASE(module, exscan); RELEASE(module, gather); RELEASE(module, gatherv); RELEASE(module, reduce); RELEASE(module, reduce_scatter); RELEASE(module, scan); RELEASE(module, scatter); RELEASE(module, scatterv); } OBJ_CLASS_INSTANCE(mca_coll_demo_module_t , mca_coll_base_module_t , mca_coll_demo_module_construct, mca_coll_demo_module_destruct);
coll_demo_module.c
该文件中主要是与module相关的函数,两个query用于确定组件是否可用,comm_query在通信域被创建时调用,用于确定在通信域上是否可用,可用的话实例化一个module结构体变量,把其中api设置成自己组件中实现的函数,最终将变量返回,此外还需设置priority,即在本通信域上的优先级,越大越先被使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 int mca_coll_demo_init_query (bool enable_progress_threads, bool enable_mpi_threads) { return OMPI_SUCCESS; } mca_coll_base_module_t *mca_coll_demo_comm_query (struct ompi_communicator_t *comm, int *priority) { mca_coll_demo_module_t *demo_module; demo_module = OBJ_NEW(mca_coll_demo_module_t ); if (NULL == demo_module) return NULL ; *priority = mca_coll_demo_priority; demo_module->super.coll_module_enable = mca_coll_demo_module_enable; demo_module->super.ft_event = mca_coll_demo_ft_event; if (OMPI_COMM_IS_INTRA(comm)) { demo_module->super.coll_allgather = mca_coll_demo_allgather_intra; demo_module->super.coll_allgatherv = mca_coll_demo_allgatherv_intra; demo_module->super.coll_allreduce = mca_coll_demo_allreduce_intra; demo_module->super.coll_alltoall = mca_coll_demo_alltoall_intra; demo_module->super.coll_alltoallv = mca_coll_demo_alltoallv_intra; demo_module->super.coll_alltoallw = mca_coll_demo_alltoallw_intra; demo_module->super.coll_barrier = mca_coll_demo_barrier_intra; demo_module->super.coll_bcast = mca_coll_demo_bcast_intra; demo_module->super.coll_exscan = mca_coll_demo_exscan_intra; demo_module->super.coll_gather = mca_coll_demo_gather_intra; demo_module->super.coll_gatherv = mca_coll_demo_gatherv_intra; demo_module->super.coll_reduce = mca_coll_demo_reduce_intra; demo_module->super.coll_reduce_scatter = mca_coll_demo_reduce_scatter_intra; demo_module->super.coll_scan = mca_coll_demo_scan_intra; demo_module->super.coll_scatter = mca_coll_demo_scatter_intra; demo_module->super.coll_scatterv = mca_coll_demo_scatterv_intra; } else { demo_module->super.coll_allgather = mca_coll_demo_allgather_inter; demo_module->super.coll_allgatherv = mca_coll_demo_allgatherv_inter; demo_module->super.coll_allreduce = mca_coll_demo_allreduce_inter; demo_module->super.coll_alltoall = mca_coll_demo_alltoall_inter; demo_module->super.coll_alltoallv = mca_coll_demo_alltoallv_inter; demo_module->super.coll_alltoallw = mca_coll_demo_alltoallw_inter; demo_module->super.coll_barrier = mca_coll_demo_barrier_inter; demo_module->super.coll_bcast = mca_coll_demo_bcast_inter; demo_module->super.coll_exscan = NULL ; demo_module->super.coll_gather = mca_coll_demo_gather_inter; demo_module->super.coll_gatherv = mca_coll_demo_gatherv_inter; demo_module->super.coll_reduce = mca_coll_demo_reduce_inter; demo_module->super.coll_reduce_scatter = mca_coll_demo_reduce_scatter_inter; demo_module->super.coll_scan = NULL ; demo_module->super.coll_scatter = mca_coll_demo_scatter_inter; demo_module->super.coll_scatterv = mca_coll_demo_scatterv_inter; } return &(demo_module->super); }
之前提到的保存现有集合通信函数及实现组件在enable函数中进行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #define COPY(comm, module, func) \ do { \ module->underlying.coll_ ## func = comm->c_coll->coll_ ## func; \ module->underlying.coll_ ## func = comm->c_coll->coll_ ## func; \ if (NULL != module->underlying.coll_ ## func ## _module) { \ OBJ_RETAIN(module->underlying.coll_ ## func ## _module); \ } \ } while (0) int mca_coll_demo_module_enable (mca_coll_base_module_t *module, struct ompi_communicator_t *comm) { mca_coll_demo_module_t *demo_module = (mca_coll_demo_module_t *) module; if (mca_coll_demo_verbose > 0 ) { printf ("Hello! This is the \"demo\" coll component. I'll be your coll component\ntoday. Please tip your waitresses well.\n" ); } COPY(comm, demo_module, allgather); COPY(comm, demo_module, allgatherv); COPY(comm, demo_module, allreduce); COPY(comm, demo_module, alltoall); COPY(comm, demo_module, alltoallv); COPY(comm, demo_module, alltoallw); COPY(comm, demo_module, barrier); COPY(comm, demo_module, bcast); COPY(comm, demo_module, exscan); COPY(comm, demo_module, gather); COPY(comm, demo_module, gatherv); COPY(comm, demo_module, reduce); COPY(comm, demo_module, reduce_scatter); COPY(comm, demo_module, scan); COPY(comm, demo_module, scatter); COPY(comm, demo_module, scatterv); return OMPI_SUCCESS; }
其余文件
一个组件在MCA架构下必须的内容就是上面这些了,接下来就是自己实现集合通信函数、算法以及为之服务的一些功能,需要注意的是没新建一个文件需要将其添加到Makefile.am的sources中。
结语
Open MPI的开发基本是以面向对象的模式开发的,向我这种在之前没有用c语言编写过面向对象程序的新手最初读代码时许多地方都会难以理解,写这篇博客希望能对以Open MPI为基础刚开始研究集合通信的新手提供一些帮助,因为自己在做毕设项目初期确实因为缺少资料遇到很多烦恼,英文资料都没有更别说中文了,可能跟这个方向的研究并不那么大众有关。语言表达能力有限所以有的地方写的可能有点难以理解,可以进一步交流或者直接通过mca设置verbose参数进行调试,从而帮助你更好的读懂代码。
最后附上几个组件对应的论文链接,论文与代码结合能更好的理解作者时如何实现的: