来自Rico-Gallego等人通信性能模型综述
作者:Juan A. Rico-Gallego, Juan C. Díaz-Martín, Ravi Reddy Manumachu, and Alexey L. Lastovetsky.
期刊:ACM Comput. Surv. 51, 6, Article 126 (January 2019)
doi:doi.org/10.1145/3284358
ACM DL URL:https://dl.acm.org/doi/abs/10.1145/3284358
对集群的通信成本进行建模是一个重要又具有挑战性的工作,它能为并行应用通信模式的设计提供帮助,并为对其的进一步优化奠定基础。这篇综述中作者总结了高性能计算领域中出现的一些主要的通信性能模型(Communication Performance Model),并提出了自己对性能模型的建立、用途、评价等问题的看法与观点。
通过这篇综述可以很好的了解通信性能模型的发展、作用,以及现有的各类集合通信模型分别做了什么、为何这样设计、有哪些进一步的贡献、优缺点等等,作者作为这一领域的研究人员在文章中还提出了许多独到的个人见解。
这篇博客的目的主要在于对文章作以总结,因此也是按照原文的结构划分章节内容。
通信性能模型简述与论文结构
“从最广泛的意义上讲,建模是为了某种认知性的目的,高效地使用某种东西来替代另一种东西。它允许我们为了达到某种目的,使用比现实情况更简单、更安全或成本更低的东西来代替现实。这使我们能够以简化的方式处理事物,避免了现实情况的复杂性与不可逆转性。”
“Modeling, in the broadest sense, is the costeffective use of something in place of something else for some cognitive purpose. It allows us to use something that is simpler, safer or cheaper than reality instead of reality for some purpose. This allows us to deal with the world in a simplified manner, avoiding the complexity, danger and irreversibility of reality.”
–Rothenberg et al. 1989[1]
现代HPC平台为了达到尽可能高的性能,发展出了十分复杂的硬件结构,集群是最普遍的一种HPC平台。对高性能计算领域而言,要分析一个组件会提升还是降低性能需要依赖软件工具进行分析,而在当前复杂的系统中,预测性能仍然是一个尚未得到满意解决方案的重大挑战。
通信性能模型现状与面临的挑战
通信性能模型如今面临的挑战主要来源于集群计算节点与网络不断增长的复杂度。集群的计算节点越来越复杂,以同一节点上的进程间通信为例,它们可以使用共享内存作为缓冲区通信,也可以通过高性能网络(如Infiniband)使用操作系统模块、操作系统旁路或远程内存访问(RMA)进行消息的直接传输。
在一个特定平台上,通信性能模型能根据一组有限的参数来表示集群通信的成本。现代HPC平台的复杂性导致经典的性能准确性较低,致使在实际优化工作中性能模型经常被抛弃,转而使用实验的方式来进行,而这种做法往往需要消耗很多的时间。因此对模型进一步优化的工作仍在继续进行:例如lognP[2]将本地或远程实体之间的数据移动称为“转移”,发送消息则被视为一连串的转移,转移的成本仅与中间件有关;τ-Lop[3][4][5]模型则是进一步解决了lognP在通信通道争夺与异构平台方面建模的弱点。
现有性能模型总结
作者认为一个通信模型可以由三个维度的因素来描述:
-
独创性(Originality)
独创性的维度中模型被分为基础模型(Foundational)和衍生模型(Derived)两种。
-
平台独立性(Platform independence)
通用的(Generic)模型可以在不同的平台上运行,而特定的(Specific)模型转为某种平台设计。
-
参数化(Parameterization)
参数化的维度分为硬件参数模型(hardware-parameterized)与软件参数模型(software-parameterized)。使用中间件带来的额外的通信开销在硬件参数模型中被直接忽略,这种额外开销同时也是软件参数化模型不准确的根源
作者将现有的主要性能模型分类总结为了下表,其中Type是按照上述三个维度进行的分类,Target Platform列出了模型适用的平台,最后是每个模型跟先前模型相比的贡献。
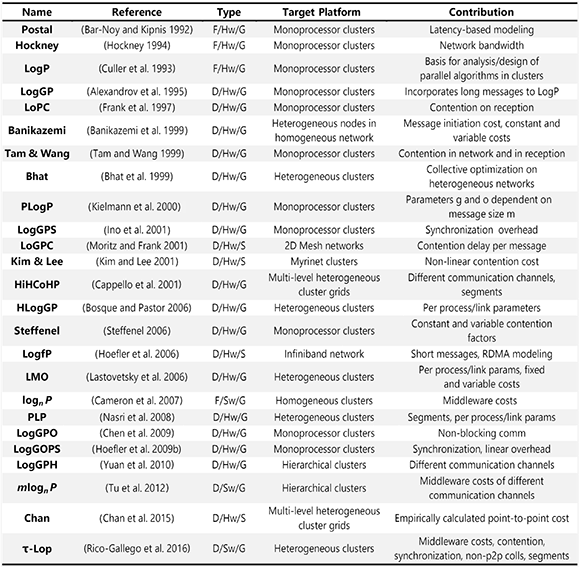
论文结构
这篇综述旨在为研究者提供一个文献指南,展示性能模型的范围、行为、优点、受限点以及模型的思想,具体章节上:
-
第2节讨论了基础模型和它们预期的适用性;
-
第3节解释了现有模型分别是如何应对现代平台带来挑战;
-
第4节讨论模型参数的设计与测量相关的问题;
-
第5节介绍了影响模型性能的主要因素;
-
最后第6节总结与展望。
基础通信模型
根据作者观点,现有的模型可被分为基础模型与派生的模型,在这一小节主要介绍基础模型的概念、形式与实际应用情况,而后者派生模型则旨在解决基础模型没有涵盖的问题,在下一节中详细介绍。
概念与形式
通讯性能模型使用一系列参数对一次点对点通信的时间消耗进行建模,点对点通信的成本可以进一步推广到集合通信当中,例如二项树通信的时间可以根据来计算。
Postal模型和Hockney模型
Postal[6]模型是出现最早的一个模型,由Bar-Noy和Kipnis提出,它们希望通过引入网络延迟对全连接网络的通信进行建模分析。Postal模型中,点对点通信的时间,模型假设同一时间一个处理器仅能发送或接收一个消息。
Hockney[7]模型通常也被称为α-β模型,他在Postal模型的基础上引入了带宽,并且限制了每次传输的数据量。Hockney模型一次点对点通信的成本,其简明的格式使它有着较为广泛的应用。在模型的假设上,Hockney模型假设一个节点可以同时执行一个发送操作和一个接收操作。
LogP模型与LogGP模型
LogP[8][9]模型名称中的四个字母代表了模型中的四项参数:
-
L:Lantency,网络延迟。发送方发送完最后一个字节到接收方接收完最后一个字节的时间。
-
o:overhead,开销。处理器为发送或接收消息花费的时间,包括准备消息、发送队列中排队、向NIC发送信号等。
-
g:gap per message,间隔。网卡向链路注入相邻两个数据包之间所需要的最小时间,其倒数反应了网络的带宽,处理器在网络中被阻塞之前能够发送个消息。
-
P:进程总数。
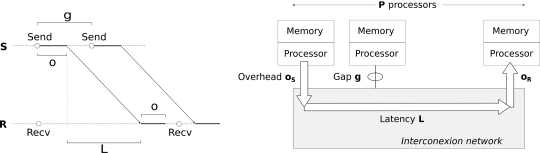
根据模型各参数的含义,发送一个短消息时时间成本,Culler[10]等人提出进一步区分发送方和接收方的开销,即与。LogP模型的主要进展是考虑到了处理器对通信延迟的影响,的存在意味着这些时间中处理器能够做一些非通信的工作,也就是可以存在计算与通信的重叠。
LogP模型有着重要的地位,同时也是后续许多模型的基础,但它的一个限制是它仅考虑短消息,对于长消息模型假设其作为一个短消息的序列进行发送。为了解决这一问题LogGP[11]模型多引入了一个参数G,gap per byte,用来向网络中注入两个字节的最小间隔,对于长消息而言即代表网络带宽,对应于Hockney中的β。
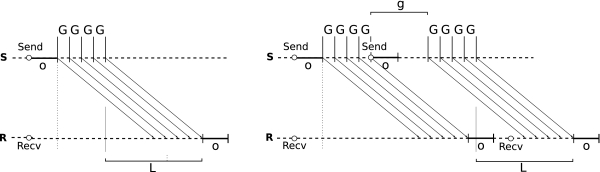
LogGP模型对网络带宽的建模无疑是更准确地,如上图所示,发送单个消息是时间成本可表示为:
而发送n个消息使为:
应用
需要应用通信性能模型的研究大多都是在MPI集合通信操作的性能调优上,除此之外作者还总结了模型在优化集群上的调度算法上的应用。
集合通信在许多高性能计算程序中占用了相当一部分的时间,因此许多研究都致力于提高MPI集合通信操作的性能,通信性能模型主要能从两点提供帮助:
-
为集合通信算法的设计提供参考
-
具体分析某一通信模式的性能
第一点主要是理论层面,分析一个集合通信算法底层的点对点通信顺序与步数,用特定某型表征它总体时间成本,从而评价模型的优劣,反过来指导算法的设计。
第二点是实践层面上,可以通过建立好的性能模型来估计某一特定集合通信算法的性能,能够基于建立与拟合好的模型算出一个具体的值,更进一步可以通过这种方法在程序中自适应地选择具体的算法实现,从而优化集合通信操作效率。例如MPICH[12]既是在运行过程中根据Hockney在多种算法中选择对于当前情况最优的一种。
反应MPI集合通信操作的性能
通信性能模型在这一方面的应用主要对应上述的第2点,此外通信模型还可以用于一些分布式系统的仿真工具,如最流行的SimGird[13],它能够支持对网格、云、P2P、HPC系统等平台的模拟,它使用的就是Hockney模型。
最佳通信规划
这一部分主要是重新组织算法中计算部分的位置,使其能尽可能与通信重叠,从而使网络中延迟和带宽造成的时间成本最小化,这里是要用模型的参数表达算法,使设计者能够解决性能的关键点。在MPI集合通信中这一应用主要对应上文所述的第1点,但性能模型在确定最佳通信规划上不仅在集合通信中有所应用:
-
Culler等人[14]使用LogP模型分析了一些应用中常用的算法实例,如广播、求和或FFT;
-
Karp等人[15]基于LogP模型给出了六个不同问题的最佳调度方案;
-
Dusseau等人[16]用LogP来模拟一组排序算法。
HPC平台与通信性能模型的发展
这一部分的内容主要介绍了衍生的通信性能模型的具体能力。基础模型提出后研究者们很快发现了它们的局限性和未解决的问题,例如MPI成本的准确预测、通道争夺、多核节点的中断等方面,同时也在在通过衍生模型解决这些问题。
MPI原语的精确建模
LogP/LogGP对机器层面上(例如Elan和Active Message两个底层通信库)通信原语的建模总体来说有着较好的性能,但对于更高级别的MPI原语来说准确性就有所不足了。
例如,接收方缓冲区大小的限制使得MPI_Send必须使用特定的协议,例如常用于短消息的Eager协议与用于长消息的Rendezvous协议。前者发送消息时假定目标有足够的存储空间,而Rendezvous的发送方在发送实际载荷前会发送一个小的控制消息,并在确认控制消息送达后再开始实际载荷的发送,这一点在LogP/LogGP中并未考虑。
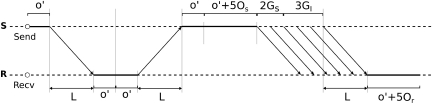
LogGPS[17]考虑了上述问题,它与LogGP相比有三点不同:
-
设定消息长度阈值S,实际消息大小时发送方需要等待接收方的ACK;
-
将overhead建模为:,发送方和接收方的overhead不同;
-
另一个长度参数s,时取,否则取。
下图为时LogGPS建模的情况:
Chen等人提出的LogGPO模型则是在计算通信重叠的角度上对LogGP模型进行了扩展,他们认为LogGP模型假设了一个过于完美的重叠度,而未考虑MPI实现中由Communication Progress Engine等模块带来的额外开销。因此LogGPO对LogGP进行了扩展以捕获MPI库的实际开销。
网络层级
Grid’5000在内的许多HPC基础设施通过广域网连接了多个集群,但集群内的局域网与连接不同集群的广域网之间网络的延迟和带宽有着几个数量级的差异,自然也会对通信性能模型的准确性带来很大影响。
Kielmann等人[18]提出的PLogP模型的目标是优化上述情况下MPI集合通信操作的性能,一方面将LogP模型中的gap与overhead两个参数变为了以消息大小m为自变量的线性函数,同时根据网络类型(LAN或WAN)将L定义为Ll与Lw。
现代HPC集群由高性能网络连接的多核节点组成,这使得“网络”的概念扩展为“具有不同能力的通道的层级结构”,Yuan[19]等人提出的LogGPH模型借助“通信级别”的概念来表示网络层次结构,如拓扑位置处于同一个插槽(Socket)内的两个进程处于第1级,彼此通过共享内存通信;第2级的通信则是同一节点,不同插槽之间的两个进程的通信;第3级别上的两个进程通过网络进行通信。LogGPH模型为不同通道(即不同层级上)的通信设定了不同的参数,第i级上的通信成本即为:
通信争用
截至目前提到的所有模型都是“无争用”模型,然而对同一通信通道的并发访问会降低它的可用带宽进而影响整体的性能,而以All-to-all为例的集合通信操作是需要对争用情况进行建模的。Tam和Wang[20]提出了两种类型的争用:
-
节点争用,即对节点上资源的竞争;
-
链路争用,即对网络链路的竞争。
LoPC[21]是第一个考虑争用的模型,模型中的争用主要发生在接收消息的线程间对处理器的争用。LoGPC[22]将LogGP扩展到Mesh网络的集群,新增一个参数来代表网络争用的影响,参数的下标n表示在K-ary N-cube的Mesh上的n维度,该参数来源于交换机的平均延迟。该模型的缺点是参数的数量会急剧增加。
平台异构
HPC平台的发展使异构系统得以出现,例如计算网格,就是一种连接全球分布式计算站点的基础设施,他的节点和网络都是异构的。
使性能模型适用异构平台的一个方法是对于模型中的部分参数,为不同的进程之间设置不同的值。例如Bhat等[23]人将Hockney模型的公式扩展为,而HLogGP[24]为每个进程设置不同的、、,同时将和扩展为一个矩阵。
中间件成本
中间件成本主要被用于多核节点集群的建模,同一节点上的进程通过共享内存通信。下图为lognP[2:1]模型的主要思想:
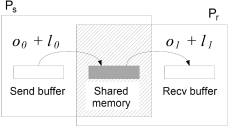
如之前在网络层级和通信争用中提到的,多核节点集群形成了多级通信通道组成的通信层级结构,中间件成本建模将这些通道当作通信的中间件,建模其通信时间成本,如开头提到的τ -Lop[3:1][4:1][5:1]模型,该模型还充分考虑了信道的争用等问题。

大规模
Hoefler等人[25]提出了LogGOPSim模拟框架用来评估大规模并行算法,其对应的模型LogGOPS基于LogGPS,进一步强调每字节的开销O,传输成本被表示为:
通用与具体化
Martinasso和Méhaut[26],以及Tam和Wang[27]均指出了一个模型两级分化的趋势,即模型要么过于笼统、理论化,要么过于针对某个特定的平台或应用。综述的这一小节主要针对该问题进行叙述。
构建模型的实验方法
文章这一节主要讨论实际测量模型参数的方法,即如何以实验的方式建立实际模型。一个模型的理论描述经常会与它在实际实验中的形式有很大不同,通过实验构建模型的过程中往往会引入一些中间参数,也被称为经验参数。这些额外的经验参数的出现一般来源于底层MPI实现的一些特异性,或是实验平台网络的一些其它性质。因此要使一个模型易于通过实验构建,就需要其具有良好的可调性,能够以较低的成本确定它的经验参数。
研究者们提出的很多通信性能模型虽然在理论上做出了很突出的贡献,但却没有严谨的介绍模型的参数要怎样在实验中测量,要想使用这些模型仅能由读者凭自己的理解编写程序,而显然如果作者在提出模型的同时给出公式、伪代码等形式的表示,可以很大程度上方便读者理解。
因此,作者认为一个模型的测量方法如果解释得不好,只会阻碍该模型的实际应用。
文献中已有构建方法
这一节中主要介绍了几个著名模型的测量方法。
LogP
Culler等人[10:1]研究了在通信层基于Active Message的平台上建立LogP模型:
-
首先利用AM的请求-回复操作测量到一个;
-
然后连续发送n个请求,n比较小使发送方仅用处理发送请求,此时发送每个请求消息的平均耗时被当作,而随着n增大,此时网络逐渐饱和,最终发送每个消息的耗时变为;
-
仅使用RTT的话参数无法测量,因为消息发送后会空闲一段时间,回复消息到了之后再花费长的时间来处理,不能确定开始处理的时间点,因此需要引入一个受控制的计算量Δ,发送消息后花费Δ长的时间计算,由于计算与处理回复消息都会占用CPU时间,因此就可以通过多花费的计算时间得出。
-
最终通过算出L。
LogGP
Hoefler等人[28]提出了一个精心设计的测量方法来建立LogGP模型,其方法的基本构件被称为“the parametrized round trip time (PRTT)of a ping-ping message”。
在其方法中,一个延迟的ping-ping消息PRTT为:
在有延迟的情况下(为d):
可以得出:
具体参数的计算:
-
当,可以算出;
-
否则,可以根据一系列结果通过最小二乘法拟合得到与;
-
被简化为小消息的PRTT,即。
其余模型
处上述两个之外还介绍了PLogP、LMO、lognP、τ –Lop四个模型的构建方式,除了使用往返时间RTT,还利用了单个Ping操作的时间、Ring操作的时间等方法。
评估构建方法的框架
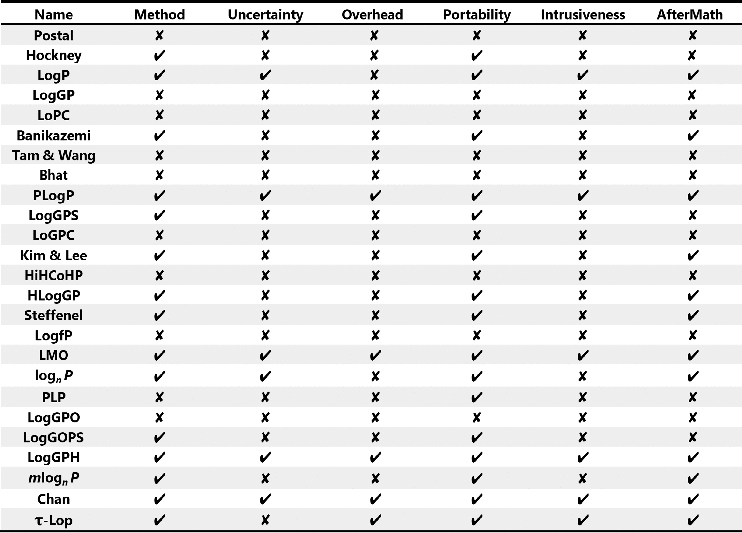
正如这一小节的标题,作者指出了如何去评估一个构建方法,按照首字母缩写为“MUOPIA”:
-
Method:模型作者需要清楚定义每个参数所对应的意义,以及要如何测量,最理想的情况是提供一个自动测量程序;
-
Uncertainty:测量方法在统计学上必须是合理的,模型中的参数必须有一个区间,好的方法还应量化误差如何随系统规模变化;
-
Overhead/Complexity:复杂度,建立模型的时间与所需信息的数量;
-
Portability/Platform Specificity:是否方便移植;
-
Intrusiveness:测量方法中的固有干扰须在测量后加以纠正,另一种干扰来自环境;
-
AfterMath:在完成了模型分析与构建方法的描述后还应做的工作:
- 为消除噪音进行的数据清理和后验统计;
- 模型在降低复杂度上的努力;
- 对模型预测的分析;
- 对模型最大误差、平均误差的分析;
- 通过软件包实现自动构建模型。
下图为已有模型在这些方面的表现:
最好的测量方法
在这一节中,作者描述了一个程序,它将展示在给定平台上确定通信模型参数值时应采用的最佳做法,博客中不再做详细的叙述。
实际模型的建立
通信性能模型的目的是对算法的通信成本进行准确估计,并对特定平台上的通信进行有意义的分析表示,以帮助做出优化的决定。接下来的内容是影响模型性能的因素,即参数测量的问题以及模型的表示方式和设计中做出的假设带来的影响。
构建程序的精度问题
影响精度的主要有两个方面。
基准测试工具
能用于测量模型参数的用户工具严重不足,这主要是因为现有平台的架构、中间件、操作系统均有区别,直接使用Micro-Benchmark程序会涉及到几个与平台相关的问题,入缓冲区重用、缓存失效、同步时间等,这些都会影响测量精度。
除了要解决存在的问题,工具还要提供可调整的选项,入最大/小消息量、重复次数、执行时间等。
可复现的Micro-Benchmark
参数测量存在固有的不准确性,造成原因有很多种,如系统噪声、争用。重点是必须使用统计方法来提高测量准确性,可用的方法如多次运行取平均、线性回归法、增加多种通信模式、调参等等。
为了减少参数测量的这种不确定性需要每个性能模型指定一个精确的测量程序,该程序必须足够灵活,以适应不同的平台。此外,这样的程序页有助于精确定义测量程序的一个基本前提是对参数进行明确的定义,也利于读者理解通信的模型表示。
作者总结的其他因素
除了上述困难外,作者还总结了一些其他的因素,它们会大大影响测量的结果,应在MPI实验的设计中加以考虑:
-
底层MPI库的差别;
-
不同的MPI标准通信模式;
-
在估计参数时,必须考虑到点对点的机制,如消息的分段;
-
Micro-Benchmark中的内部缓冲区与缓存命中情况;
-
模型的构建需要和使用模型的环境一致。
模型的设计与表现
作者认为根据模型参数的定义及其代表的内容,可以确定两种类型的模型,第一种是如主流的LogP、LogGP及其衍生的模型,它们的参数代表着网络相关特征的参数,用延迟、带宽等类似的参数来建立通信性能模型。而这一类模型的主要缺点来源于对复杂通信模式表达能力不足,同时不能很好的应对HPC平台不断增长的复杂性:
-
简化了对集合通信操作的表示,如Scatter和递归加倍的Allgather的建模结果相同;
-
现代HPC平台复杂性的增长推进了LogP/LogGP新模型的出现,它们增加了各种各样的新参数,在很多方面都较原始模型取得了提升,但仍存在问题,如对处理器物理拓扑结构的忽视等;
-
通信的一些特性很难或不可能用网络相关参数来表示,这种特性与平台中使用的通信中间件有关。如通过消息分段改善点对点的通信、通过操作系统旁路的数据直接移动等,这些会导致不同MPI库执行同一算法时有不同时间成本。
另一类新形式的模型似乎可以解决上面的问题,如lognP、mlognP、τ-Lop等,它们精度的损失更小。
模型的假设还会产生其他的问题。
LogGP假设消息的传输成本与消息大小呈线性关系,即G为发送一个字节的成本,这种方法需要精确的测量和统计方法来逼近参数值,以准确预测点对点传输的成本。它对集合通信等复杂操作预测并不精准。
模型做出的另一个假设是通信成本的大小只受算法的执行阶段树、进程数影响。一些模型为了避免这样过度的简化考虑了其它的争用情况。此外几乎所有模型都假设通信在所有进程上是同步开始的,没有对等待时间建模,实际中并不是如此。
通信模型一般还会假设在一个全连接网络上运行,部分模型用来表示Mesh、Hyper-Cube等具体的网络,如果能改进模型使它们不在仅仅适用于它们所假设的情况,那么其可用性将大大提升。
评估模型是否良好的参考框架
在这一节中,作者提出了一个参考框架来确定一个模型的整体良好性。该框架有三个维度:
-
可重复性,能在不同平台上复现;
-
构造性,可以用于多种情况下的通信建模,点对点、集合等等;
-
可扩展性/可调整性,易于扩展,以提高在不同情况下的精度。
参考文献
Jeff Rothenberg, Lawrence E. Widman, Kenneth A. Loparo, and Norman R. Nielsen. 1989. The nature of modeling. In Artificial Intelligence, Simulation and Modeling. John Wiley and Sons, 75–92. ↩︎
K. W. Cameron, R. Ge, and X. H. Sun. 2007. logm P and log3 P : Accurate analytical models of point-to-point communication in distributed systems. IEEE Transactions on Computers 56, 3 (2007), 314–327. ↩︎ ↩︎
J. A. Rico-Gallego, J. C. Díaz-Martín, and A. L. Lastovetsky. 2016. Extending τ –Lop to model concurrent MPI communications in multicore clusters. Future Generation Computer Systems 61 (2016), 66–82. ↩︎ ↩︎
J. A. Rico-Gallego and J. C. Díaz-Martín. 2015. τ –Lop: Modeling performance of shared memory MPI. Parallel Computing 46 (2015), 14–31. ↩︎ ↩︎
J. A. Rico-Gallego, A. L. Lastovetsky, and J. C. Díaz-Martín. 2017. Model-based estimation of the communication cost of hybrid data-parallel applications on heterogeneous clusters. IEEE Transactions on Parallel and Distributed Systems 28, 11 (Nov 2017), 3215–3228. ↩︎ ↩︎
Amotz Bar-Noy and Shlomo Kipnis. 1992. Designing broadcasting algorithms in the postal model for message-passing systems. In Proceedings of the 4th Annual ACM Symposium on Parallel Algorithms and Architectures (SPAA’92).ACM, New York, NY, 13–22. ↩︎
Roger W. Hockney. 1994. The communication challenge for MPP: Intel paragon and Meiko CS-2. Parallel Computing 20, 3 (March 1994), 389–398. ↩︎
David Culler, Richard Karp, David Patterson, Abhijit Sahay, Klaus Erik Schauser, Eunice Santos, Ramesh Subramonian, and Thorsten von Eicken. 1993. LogP: Towards a realistic model of parallel computation. In Proceedings of the 4th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPOPP’93).ACM,NewYork,NY,1–12. ↩︎
David E. Culler, Richard M. Karp, David Patterson, Abhijit Sahay, Eunice E. Santos, Klaus Erik Schauser, Ramesh Subramonian, and Thorsten von Eicken. 1996a. LogP: A practical model of parallel computation. Communications of the ACM 39, 11 (November 1996), 78–85. ↩︎
David E. Culler, Lok Tin Liu, Richard P. Martin, and Chad O. Yoshikawa. 1996b. Assessing fast network interfaces. IEEE Micro 16, 1 (Feb. 1996), 35–43. ↩︎ ↩︎
Albert Alexandrov, Mihai F. Ionescu, Klaus E. Schauser, and Chris Scheiman. 1995. LogGP: Incorporating long messages into the LogP model - one step closer towards a realistic model for parallel computation. In Proceedings of the 7th Annual ACM Symposium on Parallel Algorithms and Architectures (SPAA’95). New York, NY, 95–105. ↩︎
MPICH. 2013. Argonne National Laboratory. Retrieved September 25, 2022 from https://www.mpich.org. ↩︎
Henri Casanova, Arnaud Giersch, Arnaud Legrand, Martin Quinson, and Frédéric Suter. 2014. Versatile, scalable, and accurate simulation of distributed applications and platforms. Journal of Parallel and Distributed Computing 74, 10 (June 2014), 2899–2917. ↩︎
David Culler, Richard Karp, David Patterson, Abhijit Sahay, Klaus Erik Schauser, Eunice Santos, Ramesh Subramonian, and Thorsten von Eicken. 1993. LogP: Towards a realistic model of parallel computation. In Proceedings of the 4th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPOPP’93).ACM,NewYork,NY,1–12. ↩︎
Richard M. Karp, Abhijit Sahay, Eunice E. Santos, and Klaus Erik Schauser. 1993. Optimal broadcast and summation in the LogP model. In Proceedings of the 5th Annual ACM Symposium on Parallel Algorithms and Architectures (SPAA’93).ACM, New York, NY, 142–153. ↩︎
Andrea C. Dusseau, David E. Culler, Klaus Erik Schauser, and Richard P. Martin. 1996. Fast parallel sorting under LogP: Experience with the CM-5. IEEE Transactions on Parallel Distributed Systems 7, 8 (Aug. 1996), 791–805. ↩︎
Fumihiko Ino, Noriyuki Fujimoto, and Kenichi Hagihara. 2001. LogGPS: A parallel computational model for synchronization analysis. SIGPLAN Notes 36, 7 (June 2001), 133–142. ↩︎
Thilo Kielmann, Henri E. Bal, Sergei Gorlatch, Kees Verstoep, and Rutger F. H. Hofman. 2001. Network performanceaware collective communication for clustered wide-area systems. Parallel Computing 27, 11 (2001), 1431–1456. https: //doi.org/10.1016/S0167-8191(01)00098-9 ↩︎
Liang Yuan, Yunquan Zhang, Yuxin Tang, Li Rao, and Xiangzheng Sun. 2010. LogGPH: A parallel computational model with hierarchical communication awareness. In IEEE 13th International Conference on Computational Science and Engineering (CSE’10). IEEE, 268–274. ↩︎
A. T. C. Tam and Cho-Li Wang. 2003. Contention-aware communication schedule for high-speed communication. Cluster Computing 6, 4 (2003), 339–353. ↩︎
Matthew I. Frank, Anant Agarwal, and Mary K. Vernon. 1997. LoPC: Modeling contention in parallel algorithms. In Proceedings of the 6th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPOPP’97).ACM,New York, NY, 276–287. ↩︎
Csaba Andras Moritz and Matthew I. Frank. 2001. LoGPC: Modeling network contention in message-passing programs. IEEE Transactions on Parallel and Distributed Systems 12, 4 (April 2001), 404–415. ↩︎
Prashanth B. Bhat, Viktor K. Prasanna, and C. S. Raghavendra. 1999. Adaptive communication algorithms for distributed heterogeneous systems. Journal of Parallel and Distributed Computing 59, 2 (Nov. 1999), 252–279. ↩︎
J. L. Bosque and L. Pastor. 2006. A parallel computational model for heterogeneous clusters. IEEE Transactions on Parallel and Distributed Systems 17 (2006), 1390–1400. ↩︎
Torsten Hoefler, Timo Schneider, and Andrew Lumsdaine. 2010. LogGOPSim: Simulating large-scale applications in the LogGOPS model. In Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing (HPDC’10). ACM, New York, NY, 597–604. ↩︎
Maxime Martinasso and Jean-François Méhaut. 2011. A contention-aware performance model for HPC-based networks: A case study of the InfiniBand network. In Proceedings of the 17th International Conference on Parallel Processing — Volume Part I (Euro-Par’11). Springer, Berlin, 91–102. ↩︎
A. T. C. Tam and Cho-Li Wang. 1999. Realistic communication model for parallel computing on cluster. In Proceedings of the 1st IEEE Computer Society International Workshop on Cluster Computing. IEEE, 92–101. ↩︎
T. Hoefler, T. Schneider, and A. Lumsdaine. 2009a. LogGP in theory and practice: An in-depth analysis of modern interconnection networks and benchmarking methods for collective operations. Simulation Modelling Practice and Theory 17, 9 (2009), 1511–1521. ↩︎