SmartNIC&GPU Direct相关论文阅读
GPU Direct与SmartNIC、DPU、FPGA实现与上层应用相关论文阅读。
- FpgaNIC: An FPGA-based Versatile 100Gb SmartNIC for GPUs
- SplitRPC: A Control + Data Path Splitting RPC Stack for ML Inference Serving
- Lynx: A SmartNIC-driven Accelerator-centric Architecture for Network Servers
FpgaNIC: An FPGA-based Versatile 100Gb SmartNIC for GPUs
usenix atc 22
Collaborative Innovation Center of Artificial Intelligence, Zhejiang University
https://www.usenix.org/conference/atc22/presentation/wang-zeke
提出一个基于FPGA、以GPU为中心的多功能智能网卡,可以使用GPU虚拟地址与本地GPU直接进行PCIe p2p通信,为远程GPU提供100Gb可靠网络访问。
认为GPU对Smart NIC的需求:
-
能触发doorbell与轮询状态寄存器
-
通过虚拟地址访问GPU内存
-
硬件网络栈
-
应用程序的软硬件卸载
-
data-path加速器易于编程
硬件选择: PCIe-based Xilinx FPGA board Alveo U50
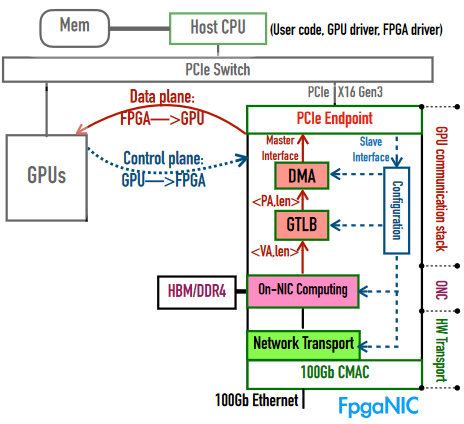
整体架构:
-
GPU communication stack
- 使FPGA能使用GPU虚拟地址直接访存
- GPU能够访问FPGA的dorebell寄存器初始化数据传输
-
Reliable Network Transport in Hardware
提供低延迟、高吞吐量、可靠的网络访问
-
on-NIC Computiong
- 实现high level编程接口
- 实现direct、on-path、off-path三种模式
GPU communication stack
将通信的控制平面卸载到GPU,数据平面卸载到FPGA,从而实现CPU bypassed
控制平面卸载
使GPU直接访问FPGA的控制与状态寄存器
如何卸载
硬件层面:在FPGA的PCIe IP核上启动一个PCIe BAR,暴露了一个可配置的FPGA地址空间。软件层面:实现了GPU Dirver、FPGA Dirver、与二者交互的用户空间代码。
卸载后的控制流程:
-
FPGA Dirver调用
misc_register,作为一个IO设备在Linux内核中注册PCIe BAR -
user code使用mmap将设备映射到host address
-
user code利用CUDA的内存管理功能注册主机内存供在CUDA内核中使用
卸载的意义
-
启动控制平面卸载后,FPGA上的GPU通信栈、ONC、网络传输等组件所实例化的doorbell/status寄存器能被映射到GPU虚拟地址空间,GPU能够无需CPU干预访问这些寄存器
-
能在FPGA上填充GPU TLB条目,时FPGA在发出DMA操作前将虚拟地址转换为物理地址
数据平面卸载
在NVIDIA GPUDirect的帮助下FPGA是可以直接通过物理地址PCIe p2p通信访问GPU内存的,而为了便于编程,FPGA需要在GPU的虚拟地址上工作。因此FPGA上需要存储所有相关的虚拟地址转换为物理地址的条目。为了减少开销片上,研究中将所有条目都存在片上的存储器中,但GPU所需的条目数超出了FPGA能够在不影响时序的条件下的容纳上限。
解决有效访问问题
作者提出了一个GPU转化旁路缓冲器(GTLB)在FPGA上执行地址转换。GTLB的设计关键是:在2MB的粒度上,一片连续的虚拟地址空间大概率在物理上是连续的(即连续的32个64KB大小的内存页面)。因此可以将32个连续的64KB内存页合并为一个2MB的页,作者提出如图算法,GTLB由main TLB和complementary TLB组成,主TLB提供2MB页的虚拟地址到物理地址转换,如果一个2MB页是不连续的,在补充TLB里提供对应的32个64KB页到物理地址的转换。可以有最多2048个补充TLB条目。

实际使用的策略是,为每个应用预先填充TLB条目。当发生GTLB miss/eviction时,需要为成功的GPU引用重新填充TLB条目。
Hardware Network Transport
FpgaNIC建立在100Gb TCP/IP协议栈[1][2]的基础上,该协议栈能够通过外部FPGA内存缓冲支持数千个连接,并使用外部FPGA内存进行缓冲。
原生的TCP协议栈在收发数据包前需要在TCP协议栈和应用代码之间进行控制握手,为期10到30周期,而数据包有效载荷(最大1460B)仅需23周期,导致网络带宽利用率低。为了减少握手的开销,作者引入了解耦接口使控制握手与数据传输重叠,自动将数据流分割成适当大小的数据块,可以支持最大4GB的数据。
On-NIC Computing
ON-NIC计算模块位于GPU通信栈模块和100Gbps网络硬件传输模块之间,因此ONC可以直接操纵其他两个模块,从而围绕以GPU为中心的SmartNIC实现灵活的设计空间探索。
High-Level接口
建立在HLS上,使用户可以使用c/c++操作FPGANIC。
GPU通信展提供了两个操作接口,一个是GPU访问FPGA寄存器的几口,另一个是FPGA访问GPU存储器的接口。
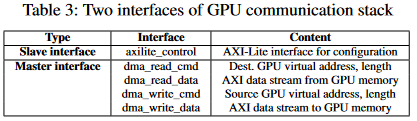
硬件网络传输主要提供数据接口与控制接口两类
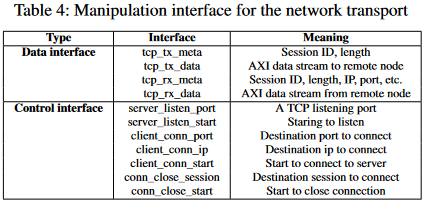
对实现direct、on-path、off-path三种Smart NIC模式的支持
-
Direct Model将GPU通信栈模块直接暴漏给GPU,以此由GPU直接操纵网络传输
-
On-Path Model与Direct模型相似,GPU直接操纵网络传输u,但也允许网络流进入ONC组件中卸载计算。
-
Off-Path Model时ONC组件中的Off-Path引擎可以直接操纵GPU通信栈和网络传输,使F怕噶NIC可以协调所有三个组件之间的数据流。
SplitRPC: A Control + Data Path Splitting RPC Stack for ML Inference Serving
Proc. ACM Meas. Anal. Comput. Syst.
The Pennsylvania State University, USA
服务器提供ML推理的服务,由客户端通过RPC进行调用,传统情况下由主机CPU为请求协调服务,本文研究的重点是将这些工作扩展到智能网卡上进行,提出了SplitRPC将RPC堆栈分解与复用成控制流和数据流,在CPU、GPU、NIC上分别管理,避免卸载中的低效问题。
背景
RPC Tax–处理RPC过程中,序列化反序列化、客户端服务器处理开销、数据移动开销
传统场景下RPC税相对很小,但在ML模型中较为显著
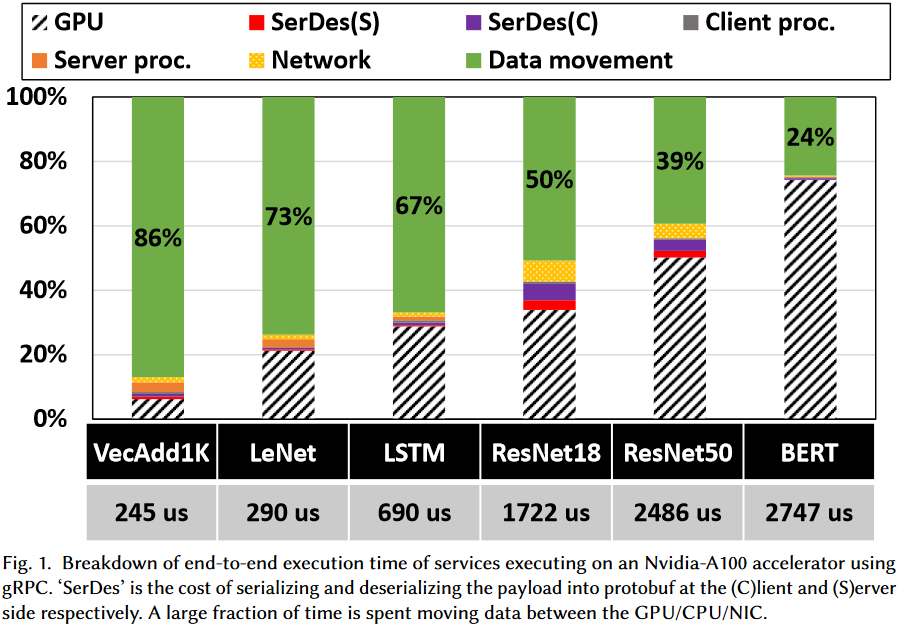
ML中的RPC
这样的RPC需要具备:
-
用于ML推理的数据请求响应格式
-
后端推理框架与ML模型运行在输入数据上
N-Network transport stack
RPC中通常用UDP接收请求与进行响应,接收到之后,请求要么保存在NIC的DRAM中,要么保存在主机或GPU的内存中。请求可以分为Control和Data两部分:
-
Control ©:要执行什么任务,调用哪个过程,可以有两种控制流路由策略
- C1:网卡将控制数据传回CPU处理
- C2:直接传到GPU
-
Data (D):请求的参数,类似可以有两种模式
- D1:先传回主机CPU
- D2:传到GPU
O-ML推理任务协调
两种方式:
-
CPU管理 (O1):在CPU上运行的ML推理框架管理模型中所有Kernel的启动与协调。启动Kernel存在额外成本但控制与同步能力强
-
GPU管理 (O2):内核的运行由GPU触发。需要在GPU上持续运行Kernel,计算本身等待开始执行,通过同步标志收到信号后模型的Kernel直接启动,多个Kernel间很难协同。GPU上这种机制被称为CUDA动态并行[3]
SplitRPC
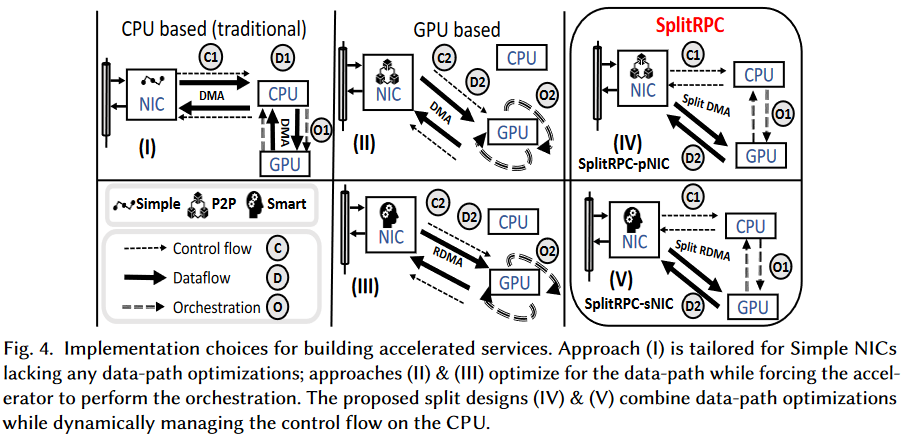
主要还是让CPU进行协调并把数据直接传给GPU。
分离RPC
在UDP协议头之上加了一个小的服务头,用它来传输请求响应的控制信息。
P2P网卡:创建两个内存区域分别位于主机内存与GPU内存,对网卡的Scatter-Gather DMA引擎进行编程,能分发64B的控制部分到CPU内存,并将Data发送到GPU的内存缓冲区。NIC完成操作后CPU收到包含Control以及Data地址信息的门铃通知
SmartNIC:arm核在NIC的DRAM上为Control和Data分配两个独立的内存区域,接收到数据包后将其在DRAM上进行拆分,最后仅将Data部分通过RDMA传到GPU特定应用内存中
两个网卡上的分离都用DPDK实现
其他部分
关于ML应用的数据传输、整体协调机制,暂时不关注
Lynx: A SmartNIC-driven Accelerator-centric Architecture for Network Servers
ASPLOS '20
Technion-Israel Institute of Technology’
Lynx,以加速器为中心的网络服务器架构,将数据平面控制平面卸载到网卡,通过轻量级硬件友好的IO机制从加速器直接联网。
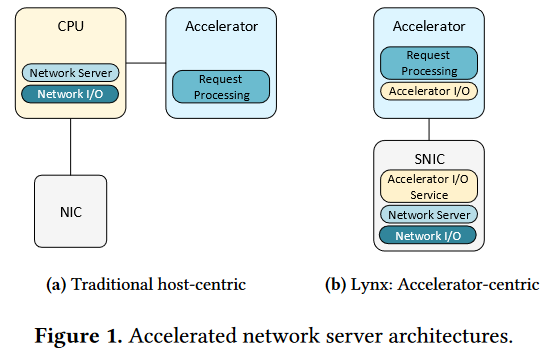
与传统基于CPU的架构相比,Lynx能提供:
-
加速器端轻量网络访问,不仅支持RDMA,提供的API原生支持TCP/UDP,并支持多种类型加速器
-
高CPU效率,把CPU从网络处理和加速器管理任务中解放出来
-
性能隔离,在智能网卡驱动的硬件加速服务和其它并行运行的应用程序之间
Lynx将网络服务器逻辑卸载到智能网卡上,在网卡上运行完整网络栈与一个通用网络服务器,监听应用程序指定的端口,传递关于加速器的数据信息。
总体设计
Lynx总体设计是加速服务运行在一台或多太物理机的加速器上,SNIC运行一个通用网络服务器作为网络服务的前端,客户端通过TCP/UDP协议与服务连接,而内部SNIC通过RDMA访问远程网卡,同一机器内通过PCIe点对点DMA进行通信。
设计目标:
-
为加速器提供网络IO
-
避免在加速器上执行调度逻辑
-
将加速器的IO操作卸载到SNIC
-
保持加速器间的可移植性
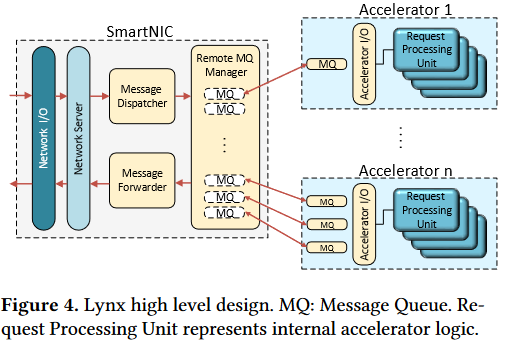
Network Server:处理网络请求,并将消息转发到加速器。入口端Message Dispatcher将收到的消息派发到适当的消息队列,取决于派发策略;出口端,Message Forwader从队列中取出消息并发送到相应目的地。
Message Queues:加速器和SNIC间传递信息。由两个环形缓冲区接收队列RX、发送队列TX,通知、完成寄存器等组成。mqueue以及它们的状态寄存器位于加速器本地的内存中,可以有效减少加速器端开销。
Remote Message Queue Manager:维护加速器中的队列,在SNIC上运行,使用单边RDMA访问加速器上的mqueue。使用RDMA让Lynx的接口能够独立于加速器,仅需依赖网卡的RDMA引擎以及PCIe点对点能力。
Accelerator-side networking
mqueue的目标是支持服务器常见的通信模式,不必提供POSIX Socket的所有接口。
server mqueue适用类似RPC的简单请求-响应交互,从加速器的角度server mqueue是一种无连接的消息传递抽象,类似UDP,其收到的mqueue收到的两条信息可能来自不同的客户端,但发回时只发给最初收到的哪个客户端。
client mqueue向其他服务器发送信息并接收它们的响应,不能重复用于不同的目的地,而是在初始化时分配目的地址。
CPU在加速器上初始化加速器内存中的mqueue,并在SNIC上配置网络服务器,提供mqueue指针,之后会调用加速器处理传入的请求并保持空闲,加速器和SNIC以轮询的方式通过mqueue通信。
加速器硬件需求
满足两个要求:
-
在支持RDMA的网卡和加速器间实现点对点PCIe DMA,加速器需要能通过BAR在PCIe上公开内存
-
为了允许SNIC和加速器通过RDMA进行交互,加速器必须能强制执行内存排序()通过BAR使PCIe地址访问也满足排序规则。
Reference
M. Ruiz, D. Sidler, G. Sutter, G. Alonso, and S. LópezBuedo. Limago: An FPGA-Based Open-Source 100 GbE TCP/IP Stack. In FPL, 201 ↩︎
D. Sidler, G. Alonso, M. Blott, K. Karras, K. Vissers, and R. Carley. Scalable 10Gbps TCP/IP Stack Architecture for Reconfigurable Hardware. In FCCM, 2015 ↩︎
Stephen Jones. 2012. Introduction to dynamic parallelism. In GPU Technology Conference Presentation, Vol. 338. NVIDIA, Santa Clara, CA, 2012. ↩︎