Mohammadreza Bayatpour等人两篇Allreduce的文章
作者团队的两篇文章都是对Allreduce操作的优化,但优化的角度不同,一个是针对配备了高吞吐量RDMA系统下大消息的Allreduce进行优化,另一篇则是对大规模Allreduce操作使用数据分片、多领导技术进行优化,二篇文章的优化内容一定程度上能够互补。
SALaR: Scalable and Adaptive Designs for Large Message Reduction Collectives
作者:Mohammadreza Bayatpour;Sourav Chakraborty;Hari Subramoni等人
会议:2018 IEEE International Conference on Cluster Computing (CLUSTER)
doi:10.1109/CLUSTER.2018.00014
IEEE Xplore URL:https://ieeexplore.ieee.org/abstract/document/8514855
作者认为在配备了高吞吐量RDMA的多核系统上,Allreduce可以利用好几个软硬件特性来提高通信性能,文章Allreduce操作也是从这5个方面出发进行设计:
-
节点间的单边通信。RDMA提供的单边通信功能write/read
-
零拷贝的节点内归约。CMA、KNEM、LiMIC、XPMEM
-
流水线化的节点间归约。在节点间通信中,CPU的归约计算与HCA设备的通信
-
节点间归约与节点内归约的重叠
-
自适应。文章中主要是针对消息分块大小
下面从三个方面来总结文章提出的Allreduce操作如何利用到上述特性。
节点间Allreduce和节点内Reduce形成的流水线
文章的Allreduce操作是分为节点内与节点间两层来进行的,通过由节点间的Leader完成Allreduce、节点内进行reduce和bcast来完成整个Allreduce操作。在节点leader的选择上本篇文章每节点选择一个leader,作者的另一篇,也是这篇博客分享的另一篇文章中研究了每节点多leader对通信效率的提升,不过本篇文章关注于大消息的通信,多leader并行通信不会带来有效提升。
两个分层上的操作如下图所示,流水线的构建通过消息分块,并利用两个硬件分层上通信的重叠来完成。在已构建好流水线的第i迭代中,节点上的非leader进程对第i块消息进行节点内的归约,leader进程对上一次迭代中规约好的第i-1块消息进行节点间的Allreduce,二者均完成之后各节点上以leader进程为根广播i-1块消息。
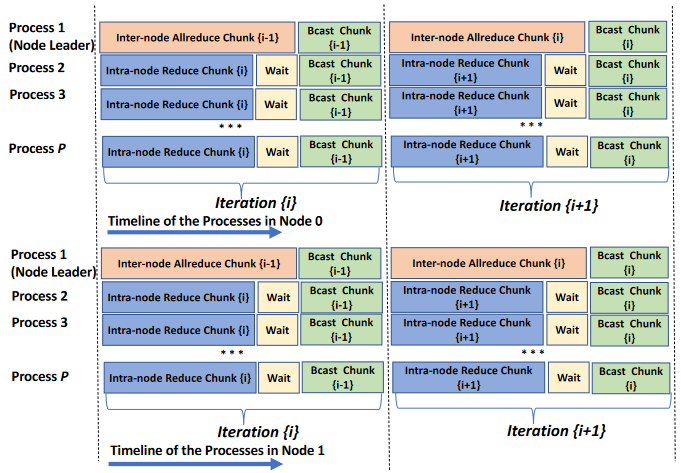
在整个过程中,将节点内的归约结果视为商品,则非leader进程相当于生产者,leader进程是消费者,节点内的reduce操作基于共享内存实现。
节点内reduce时会将当前的消息分块chunk再划分为ppn-1(即非leader进程的数量)块,首先由所有进程将自己的chunk写入共享内存,然后非leader进程i(i取1到ppn-1)对每个chunk的第i块数据执行reduce操作,所有ppn-1个非leader进程计算完成后把结果写入共享内存指定位置,组成该chunk的reduce结果。
直接使用共享内存会增加数据拷贝次数带来额外开销,可以通过KNEM、XPMEM等提供的调用来实现零拷贝的节点内数据传输。
节点间的Allreduce设计
大部分的集合通信操作都是有多个点对点通信来完成的,文章采用单边通信(one-side communication)来完成的原因是MPI大消息的点对点通信通过Rendezvous[1]协议来实现,该协议需要一次握手建立连接,带来了额外的通信开销。
节点间的Allreduce如下图所示,按节点数量P将消息分块,进程i通过read/write操作读取各进程第i块数据归约并将结果写入各进程接收缓冲区的相应位置。文章还对节点间的Allreduce做了进一步的设计。

更细粒度的流水线
进一步对刚刚介绍的已经分为p块的消息进行分块,每次进行一个小块的Allreduce可以实现通信与计算的重叠,构建出一级新的流水线。
IB链路的负载均衡
在节点间通过write/read操作进行Allreduce时若不加约束则可能造成多个进程同一时间对一个进程集中访问,造成链路拥塞,文章设置了负载均衡的机制来避免这一问题。
减少缓冲区申请开销
HCA的缓冲区注册开销较大,文章采用的方法将缓冲区统一管理,使用后不直接进行释放,减少了反复申请带来的时间开销。
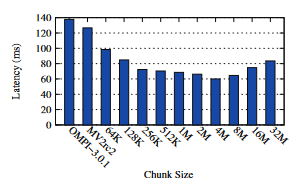
Chunk-size运行时调优的启发式策略
如图,在节点间的Allreduce的细粒度流水线中,chunk-size的大小也会影响通信效率,文章采取的策略是初始设置一个较小的chunk-size并记录实际耗时,每次调用chunk-size增大,直到增大导致性能下降,则chunk-size减半,后续均采用这一取值。
Scalable Reduction Collectives with Data Partitioning-based Multi-Leader Design
作者:Mohammadreza Bayatpour;Sourav Chakraborty;Hari Subramoni等人
会议:Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis
日期:2017.11.12
doi:10.1145/3126908.3126954
ACM DIGITAL URL:https://dl.acm.org/doi/pdf/10.1145/3126908.3126954
这篇文章也采用分层的Allreduce,区别在于没节点上选出多个leader。
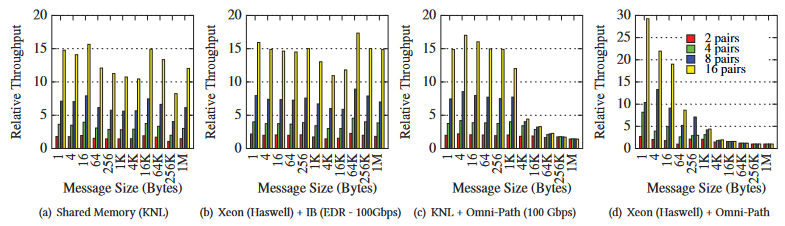
文章首先研究了多对进程并行通信情况下的吞吐量,实验结果如图,较少的进程发送一个消息时通信设备的带宽并不是通信的瓶颈,高并发的通信能够提高吞吐量。于是文章选用每节点多leader的模式进行分层。
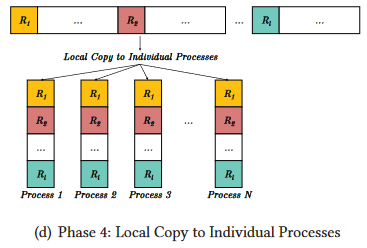
基于数据分片的多leader的Allreduce
文章的Allreduce共分为四个阶段。
第一阶段。设每个节点上运行l个leader进程,则每个进程将数据分为l份,然后拷贝到共享内存:
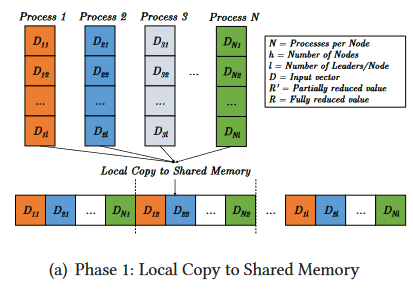
第二阶段。每个leader进程归约出一份结果:

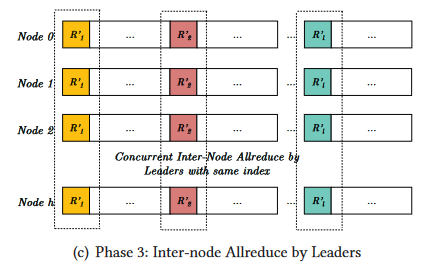
第三阶段。Leader进程执行节点间的Allreduce:
第四阶段。各进程把最终的数据拷贝到自己的接收缓冲区: