DPU Offload Collective
并行程序利用多个CPU核同时参与运算,加速问题求解。由于不同进程的数据存放在不同位置,它们之间需要通过通信进行同步与传输数据。并行程序中的通信往往需要耗费许多时间,而在此过程中CPU可以利用空余的周期进行计算操作,通信和计算的重叠对于并行程序而言有着重要意义。
为此,MPI提供了非阻塞通信函数来实现通信和计算的重叠。在MPI中,主进程对非阻塞通信函数的调用会在一些初始化操作后返回,之后通信的实际执行可以通过主线程调用MPI_Test、额外的卸载实体如子线程、硬件网络能力等功能来实现。其中,网络卸载机制具有通信操作从CPU完全卸载的潜能。
DPU常被用于卸载访问控制、入侵检测、在线压缩、传输安全加密等管理任务并被广泛地使用在数据中心中。它的网络功能与集成的CPU核使其具有集合通信操作卸载能力,卸载后,可以进一步释放主机资源,提高主机计算效率。
研究现状总结
DPU卸载集合通信的研究主要来源于DK Panda团队自2021年以来的三篇论文:
-
2021–ISC–BluesMPI: Efficient MPI Non-blocking Alltoall Offloading Designs on Modern BlueField Smart NICs
-
2021–HiPC–Large-Message Nonblocking MPI_Iallgather and MPI Ibcast Offload via BlueField-2 DPU
-
2023–IPDPS–A Novel Framework for Efficient Offloading of Communication Operations to Bluefield SmartNICs
在2021年的两篇文章中,作者分别提出了对MPI_Ialltoall、MPI_Ibcast和MPI_Iallgather的DPU卸载,虽然可以实现较好的计算通信重叠的效果,但单次数据传输需要经过本地
2021–ISC
BluesMPI: Efficient MPI Non-blocking Alltoall Offloading Designs on Modern BlueField Smart NICs
Mohammadreza Bayatpour, Nick Sarkauskas, Hari Subramoni, Jahanzeb Maqbool Hashmi, and Dhabaleswar K. Panda
DOI: 10.1007/978-3-030-78713-4_2
这篇文章[1]应该算是第一篇将集合通信操作卸载到DPU上的研究,卸载了MPI_IAlltoall操作,在Benchmark和P3DFFT的测试中取得了44%和30%的性能提升,以及通信和计算的完全重叠。
为什么集合通信可以卸载到DPU
将集合通信卸载,首先要确保DPU具有保证集合通信效率的硬件保障。作者测量了主机上运行的MPI进程的延迟带宽,与在BlueField DPU的arm核上运行的MPI进程对比,结果如下图,Relative Performance由计算得出。
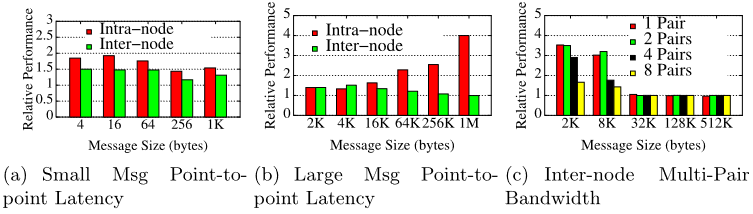
可以得出以下结论:
-
由a、b:对于Intra-Node通信,随着消息大小增加基于DPU的通信性能相对来说越来越差,主要是因为节点内通信主要依赖于CPU的消息拷贝能力,这一点DPU不占优;
-
由a、b:对于Inter-Node操作,随着消息大小增加基于DPU的通信性能与主机通信性能越来约接近,因为节点间操作主要借助HCA;
-
由c:随着消息大小增加,DPU、CPU的通信带宽越来越接近
这些结论表明DPU上的进程具有使用RDMA处理大消息密集通信的潜力,因此作者提出将中大消息的MPI_Ialltoall卸载到DPU上。
BluesMPI卸载框架
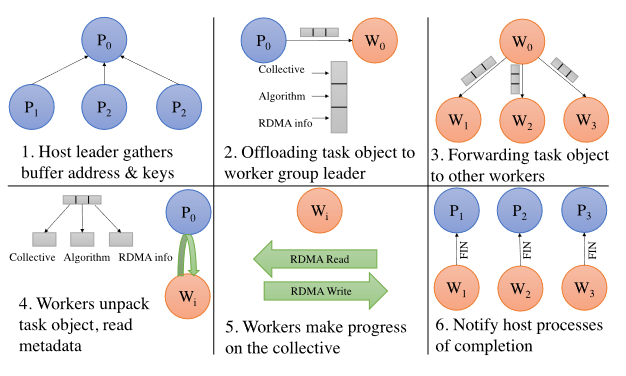
在BluesMPI中,在MPI_Init阶段会生成一系列位于DPU上的worker进程,集合通信操作被卸载到这些worker上进行。主机MPI进程只需要准备一组元数据并提供给worker进程,待其完成通信后会通知主机进程。整个流程一共有7个步骤,下图给出了后6个的示意图:
-
在HCA注册内存。主机MPI进程需要在HCA上注册接收、发送缓冲区以供远程进程做RDMA读写。BluesMPI提供了缓存机制,每块缓冲区仅需注册一次。
-
主机Leader进程收集元数据。主机节点上的其他进程将注册好缓存区的RDMA缓冲区地址、key、MPI_COMM_WORLD进程号等信息发送给Leader进程。
-
主机Leader进程在HCA上注册元数据的内存,使DPU上的worker能够访问元数据信息。注册完成后主机leader进程创建一个新的任务发给worker的leader,卸载集合通信操作,此后由DPU上的worker进程完成集合通信。DPU收到的集合通信任务由一个FIFO队列管理。
-
worker中的leader从队列拿出集合通信任务广播给worker组中其它成员。
-
worker收到元数据后解包出需要的信息。
-
执行具体的通信操作。
-
完成后告知主机进程。
DPU Offload Ialltoall算法
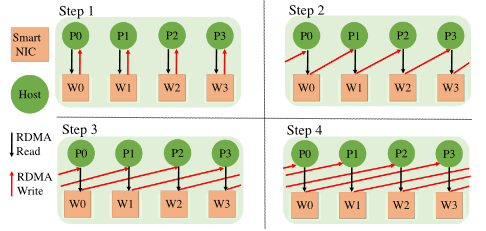
在上一节第3步的基础上可以由各worker执行Alltoall操作,文中各节点需要有均等的worker数量。BluesMPI中采取的方式是先将主机进程的数据读入DPU上worker进程的内存作为中转,再写入主机进程的接收缓存区,如下图:

由于文章主要针对中大型消息,因此采用了scatter destination算法[2]进行alltoall操作,在n(通信域大小)次迭代中将数据发送到对应远程进程的接收缓冲区。在每节点进程数、worker数都为1时,算法通信过程如下图,可以看到该算法做了负载均衡,即每次迭代一个进程的数据仅会被一个worker访问:
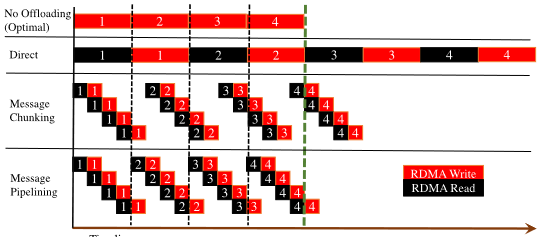
在scatter destination算法的基础上文章还提出了Direct、Message Chunk、Message Piplining三种设计。
Direct模式与上图完全一致,每个worker把分配给它的进程的发送缓冲区数据发送给其他所有进程,不做分片。Message Chunk模式将消息分成数个chunk,可以将对一个chunk的write和对下一个chunk的read进行重叠,提升效率。Message Pipline模式在分片的基础上进一步加强了overlap,可以将对一个进程最后一个chunk的write与对下一个进程第一个春困的read重叠。三个模式的示意图如下:
2021–HiPC
Large-Message Nonblocking MPI_Iallgather and MPI Ibcast Offload via BlueField-2 DPU
Nick Sarkauskas, Mohammadreza Bayatpour Tu Tran, Bharath Ramesh, Hari Subramoni, Dhabaleswar K. Panda
DOI: 10.1109/HiPC53243.2021.00054
这篇文章[^2]中作者在上一篇文章[1:1]为MPI_Ialltoall提出的卸载框架的基础上设计了DPU卸载的MPI_Ibcast和MPI_Iallgather算法。
MPI_Ibcast
本文中提出的有Flat MPI_Ibcast和Hierarchical MPI_Ibcast两种。
Flat MPI_Ibcast
步骤:
-
Read Stage:DPU root从Host root读取数据到自己的内存
-
Blocking Broadcast Stage:DPU的worker之间进行广播
-
Writeback to host:DPU其它进程把数据写到主机进程里
-
Completion Notification:告知主机进程集合通信完成
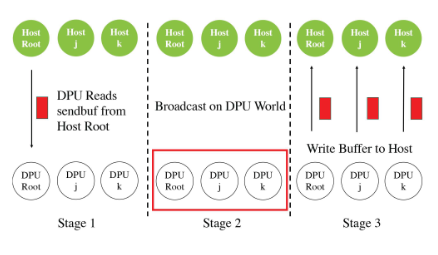
Hierarchical MPI_Ibcast
作者提出的分层MPI_Ibcast算法中,和Flat算法相比,一个主机上的进程会有一片共享内存,在worker将数据写回主机时只向host leader的共享内存写入,然后在最后收到通信完成的通知后,各主机进程从共享内存中将数据拷贝到自己的接收缓冲区。
MPI_Iallgather
和Ibcast相同,Iallgather也有Flat和Hierarchical两种。
Flat MPI_Iallgather
步骤:
-
Read Stage:每个DPU Worker都读取其节点上每个进程的sbuf,类似节点内Gather;
-
Write to Recvbuf:Worker将数据写到每个进程rbuf的指定位置;
-
Completion Notification
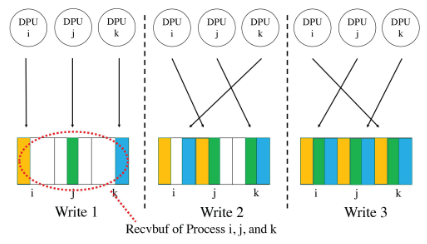
Hierarchical MPI_Iallgather
和分层Ibcast相似,先写入Host leader的共享内存,再由各进程拷贝到自己的接收缓冲区。
2023–IPDPS
A Novel Framework for Efficient Offloading of Communication Operations to Bluefield SmartNICs
Kaushik Kandadi Suresh, Benjamin Michalowicz, Bharath Ramesh, Nick Contini, Jinghan Yao, Shulei Xu, Aamir Shafi, Hari Subramoni, Dhabaleswar Panda
DOI: 10.1109/IPDPS54959.2023.00022
正如这篇文章[3]题目所说的,作者提出的框架不是单纯卸载集合通信,而是为点对点通信、其它具有点对点通信次序依赖关系的通信等均提供了卸载到DPU上的能力。在这一方面的工作中,作者提出了比MPI更高层级的接口,调用这些接口可以解决原有MPI非阻塞通信接口在一些情况下无法使通信和计算充分重叠的局限性。
下图是文中举得一个例子,在计算的过程中,各进程还在以一个环形拓扑广播一份数据,其中else分支中的MPI_Irecv和MPI_Isend之间存在先后依赖关系,因此需要等待Irecv完成之后再提交Isend。为了在通信时充分利用CPU,在通信等待期间会通过do_compute()进行计算,然而编写程序时并不知道执行计算和通信等待二者需要的时间,在下图的编程模式中就容易导致通信操作已经结束而CPU仍在计算,导致对网络资源利用率下降。

下图进一步说明了这种通信和计算不完全重叠是怎样发生的,也就是模式(1)中HCA的step1执行完成时CPU的compute1并未执行完成。如果不借助CPU之外的设备或者多线程,这一问题应该是较难避免的。模式(2)是在利用与前两篇文章类似的机制实现的通信机制,“stage mechanism”是指先将数据读到DPU内存,再写入最终目标地址。模式(3)是本文提出的框架利用了Cross-GVMI RDMA读写功能实现的通信机制,可以有DPU直接对本地Host内存发起RDMA操作,例如将远程内存读到本地Host内存或从本地Host内存网远程写入。利用这一特点能很大程度上缩短DPU卸载通信操作的通信时间。
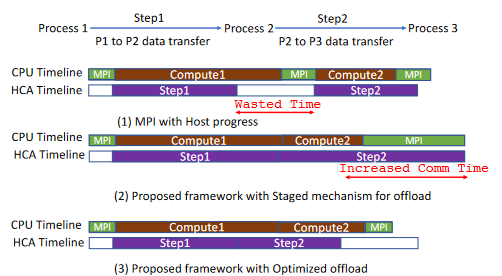
总的来说这篇文章提出了一个框架,并定义了一套API用于为任何通信模式提供基于硬件的卸载,并利用XGVMI机制解决了卸载到DPU存在的通信效率问题。
Cross-GVMI
在作者2021年前两篇对集合通信卸载的研究中可以看到,一个DPU节点上的进程要在本地Host节点和远程Host节点间进行数据传输需要使用本地内存作为暂存,连接本地和远程,也被作者称为stage mechanism。这一机制由于增加了冗余的数据传输导致效率低下。GVMI解决了这一问题,DPU进程可以在本地Host节点和远端节点的进程间传输数据。
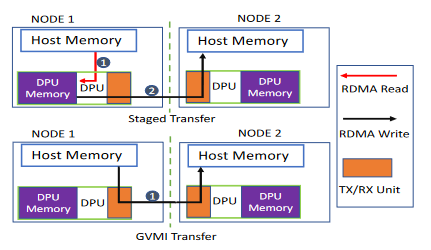
GVMI Transfer的流程如下:
-
DPU进程产生一个GVMI-ID并发送给本地Host进程;
-
本地Host进程使用GVMI-ID注册源缓冲区,并将源地址、缓冲区大小、mkey发送给DPU进程;
-
DPU注册本地Host进程源缓冲区得到mkey2,远端进程注册目的缓冲区并将相关信息发送给DPU进程;
-
DPU进程利用mkey2作为lkey执行RDMA操作,可以将读写本地Host进程源缓冲区中的数据。
通信卸载API
作者提出了Basic Primitives和Group Primitives两类API。
Basic Primitives如下图,其中Send_offload和Recv_offload类似MPI_Isend和MPI_Irecv,不过会将收发卸载到DPU上进行。

此外,Group Primitives可以在Group_Offload_start()和Group_Offload_end()之间通过调用Send_Goffload()和Recv_Goffload()初始化多个有先后顺序的发送和接收,并在适当的地方通过Group_Offload_call()来启动这一组通信。

在Group Primitives的帮助下,之前环形拓扑通信的程序可以改写为:
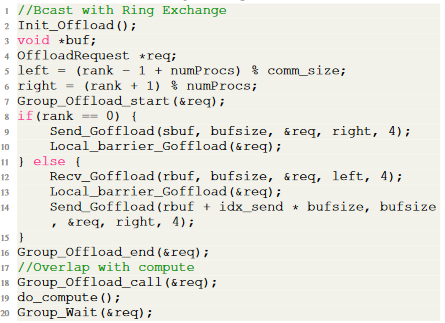
高效的DPU通信卸载机制
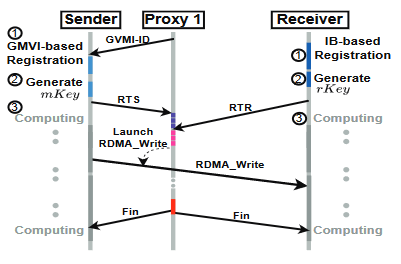
下图展示了DPU卸载的一次通信的过程。主机进程要注册DPU Proxy可用的mkey需要有DPU端提供的GVMI-ID,一个主机进程仅需使用一个GVMI-ID,因此它在Init_Offload()中生成并在所有主机与DPU进程中交换。此外Init_Offload()方法还会启动DPU上的worker进程并为其分配进程号。
在主机进程拿到GVMI-ID并选好DPU上的Proxy(Worker进程)后,会注册出mKey并向Proxy发出RTS请求,远程进程也会向同一个DPU进程发送RTR请求,Send和Recv匹配后开始正式的RDMA数据传输。
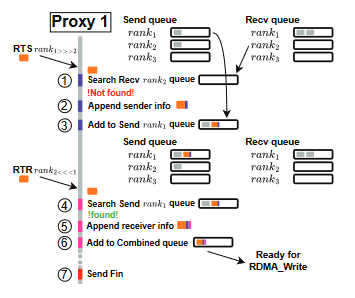
DPU上运行的Proxy进行的操作如下图。在一个RTS请求到达后,首先检测是否有目的进程提交的RTR请求,如果可以匹配则开始传输,否则向提交RTS请求的进程对应的Send Queue写入一条发送请求。同样的,接收到RTR请求后也会首先检测是否有对应的发送请求。在收发请求匹配后,Proxy会向Combined Queue中写入一条请求并等待RDMA Write的完成,最终发送Fin消息告知通信完成。
References
[^2 ]: N. Sarkauskas, M. Bayatpour, T. Tran, B. Ramesh, H. Subramoni, and D. K. Panda, “Large-Message Nonblocking MPI_Iallgather and MPI Ibcast Offload via BlueField-2 DPU,” in 2021 IEEE 28th International Conference on High Performance Computing, Data, and Analytics (HiPC), Dec. 2021, pp. 388–393. doi: 10.1109/HiPC53243.2021.00054.
M. Bayatpour, N. Sarkauskas, H. Subramoni, J. Maqbool Hashmi, and D. K. Panda, “BluesMPI: Efficient MPI Non-blocking Alltoall Offloading Designs on Modern BlueField Smart NICs,” in High Performance Computing, B. L. Chamberlain, A.-L. Varbanescu, H. Ltaief, and P. Luszczek, Eds., in Lecture Notes in Computer Science. Cham: Springer International Publishing, 2021, pp. 18–37. doi: 10.1007/978-3-030-78713-4_2. ↩︎ ↩︎
Network-Based Computing Laboratory: MVAPICH2-X (Unified MPI+PGAS Communication Runtime over OpenFabrics/Gen2 for Exascale Systems). http:// mvapich.cse.ohio-state.edu/overview/mvapich2x/ ↩︎
K. K. Suresh et al., “A Novel Framework for Efficient Offloading of Communication Operations to Bluefield SmartNICs,” in 2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS), May 2023, pp. 123–133. doi: 10.1109/IPDPS54959.2023.00022. ↩︎